了解Mysql查询语句执行流程
MySQL 逻辑架构图
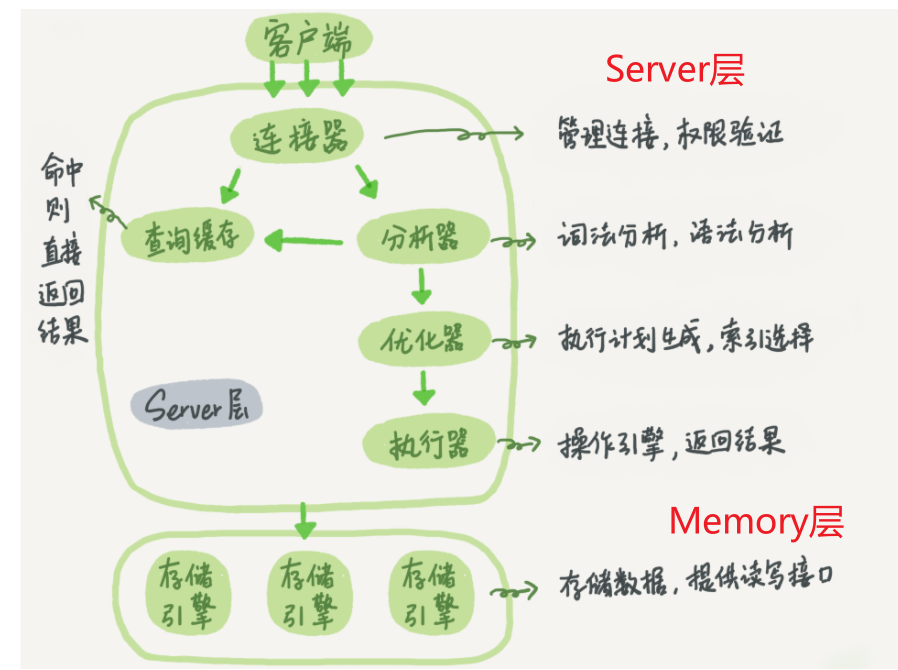
1. Server 层
Server 层包括连接器、分析器、优化器、执行器、查询缓存。
1. 连接器
作用:
- 负责跟客户端建立连接
- 获取权限
- 维持和管理连接
连接指令
1 | mysql -h$ip -P$port -u$user -p |
获取权限:通过 TCP 握手后,连接器验证身份,通过输入的用户名和密码。查询 MySQL 数据库中的 user 表。查询对应的用户权限。
长连接和短链接
长连接:连接成功后,如果客户端持续有请求,则一直使用该连接
短连接:每次执行完几次查询就断开连接,下次查询在重新建立连接。
建议使用长连接,因为建立连接过程比较复杂,尽量减少建立连接的动作。
但是建立长连接也会导致内存消耗增加。因为 Mysql 在执行时使用的内存是在连接对象里面的。这些资源会在断开时释放。
如果长连接累计下来,可能导致内存占用太大。
解决方法
- 定期断开长连接
- 执行 mysql_reset_connectionc 初始化连接资源。针对 5.7 以后。
2. 查询缓存
作用:用于做缓存
Mysql 拿到请求后会先去缓存中,查看是否有对应的查询语句。缓存以 key-value 的形式存储。
查询语句作为 key ,查询结果作为 value 存入缓存中。
但是不建议使用查询缓存。因为缓存数据失效的很频繁。
8.0 之后 MySQL 删掉了查询缓存
1 | //缓存查询 |
3. 分析器
**作用: 进行 sql 语句的解析**。
1 | select * from T where ID=1; |
- 词法分析
通过关键字 **select **识别为查询语句。将对应的 T 识别成对应的表名 T,将字符串”ID” 识别成列”ID”.
- 语法分析
判断 Sql 语句是否满足 Mysql 语法。如果语句不对,则会受到错误提醒。
4. 优化器
作用:决定执行方案
- 决定使用哪个索引,多个索引情况下。
- 决定各表连接顺序,多个表关联的情况下。
1 | select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20; |
- 既可以先从表 t1 里面取出 c=10 的记录的 ID 值,再根据 ID 值关联到表 t2,再判断 t2 里面 d 的值是否等于 20。
- 也可以先从表 t2 里面取出 d=20 的记录的 ID 值,再根据 ID 值关联到 t1,再判断 t1 里面 c 的值是否等于 10。
优化器会决定执行哪种方案。
5. 执行器
作用:执行 sql 语句
- 判断用户对这个表有无查询权限
- 根据表引擎提供的接口执行查询
- 调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
- 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
6.小结
- 连接器主要作用让客户端和服务端建立连接、获取登录用户权限、维持和管理连接。
- 查询缓存用于通过查询的 sql 语句作为 key,判断是否存在对应的 key,如果存在直接返回缓存中存储的查询结果。
- 分析器用于**判断 sql 语句语法是否正确**!将查询的 sql 语句的字段名解析成对应的数据库中对应的字段和表
- 分析器作用优化查询条件。查询条件判断使用哪种索引进行查询以及各表的连接顺序
- 执行器用于执行 sql 语句。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 无♥部落阁!
相关推荐






评论