Mysql技术内幕-第二章
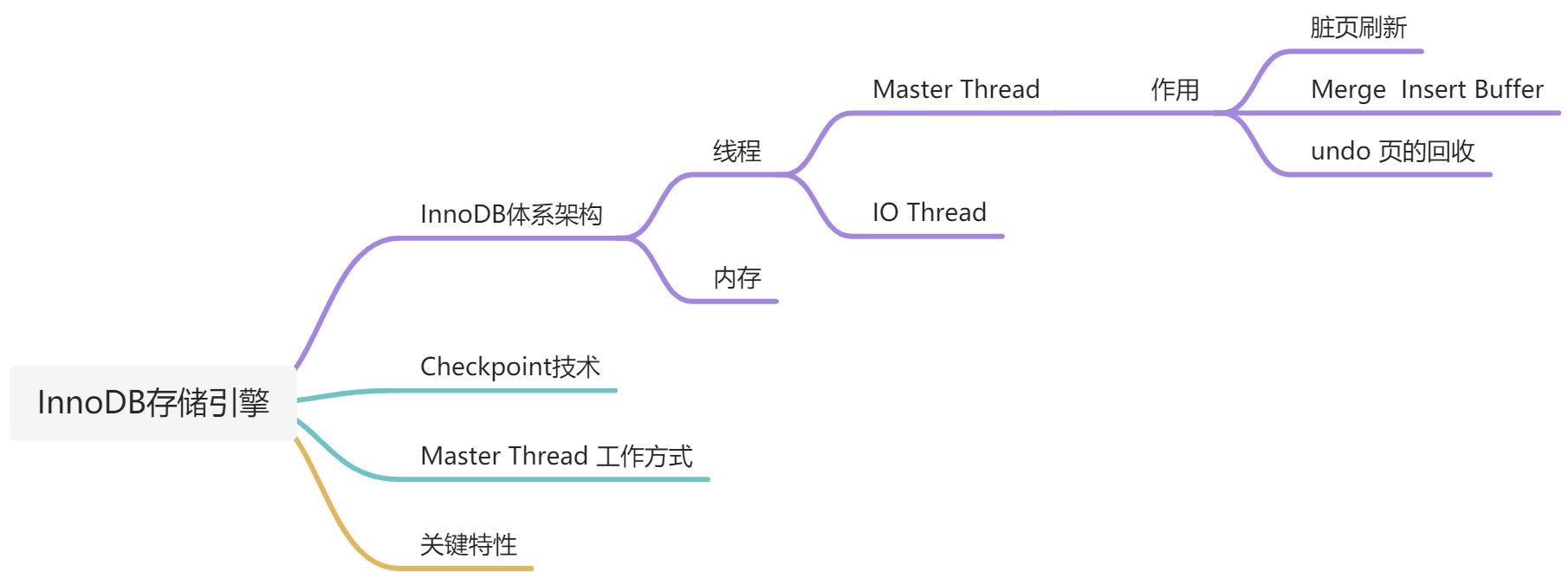
1. InnoDB 体系架构
1. InnoDB 存储引擎作用
- 缓存磁盘上的数据,方便快速读取。对磁盘数据修改之前也做缓存。
- redo log 缓冲
- 维护进程、线程需要访问的多个内部数据结构
1. 后台线程
InnoDB 存储引擎是多线程模型,负责处理不同的任务
1. MasterThread
作用
将数据异步刷新到磁盘。其中包括脏页刷新、合并插入缓冲、UNDO 页回收。
2. IO Thread
1. 作用
InnoDB 使用了大量的异步 IO 来处理 IO 请求。作用是提高数据库的性能。
IO Thread 的作用是负责IO 请求的回调处理
2. 分类
IOThread 主要分为 4 种
write thread(默认 4 个)read thread(默认 4 个)insert buffer threadlog io thread
write 和 read Thread 可以通过 innnodb_read_io_threads 和innodb_write_io_threads设置线程数

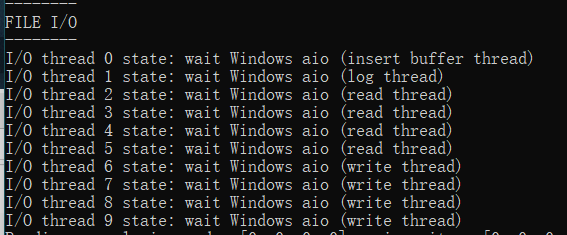
1 | //可以通过该命令查看innodb 中的io Thread |
3. Purge Thread
作用:回收事务提交后的使用的 undo 页。
分配到独立的线程中进行,减少 Master Thread 工作。同时用户可以也可以通过innnodb_purge_threads 设置线程数,默认为 1.
4. Page Cleaner Thread
作用:脏页刷新操作。
从而减少了 Master Thread 工作和查询线程线程的阻塞。提高了 InnoDB 性能。
5. 后台线程作用
- 刷新内存池中的数据,保证缓存的是最新的数据
- 将已修改的数据文件刷新到磁盘中
- 保证数据库发生异常恢复正常
2. 内存
1. 缓冲池
1. 作用
用来解决 cpu 速度和磁盘速度之间的鸿沟
2. 执行流程
数据库读取页时,将磁盘读取到的页放在缓冲池中。下一次再次读取该数据页时,直接从池中读取。否则从磁盘上读取。
数据库修改页操作时,首先修改缓冲池的页,然后通过check point 机制将数据页刷新到磁盘中。
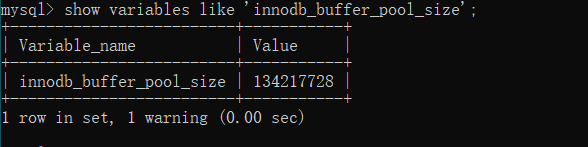
3. 缓冲池大小配置
通过 innnodb_buffer_pool_size 来设置缓冲池大小。
4. 存储对象
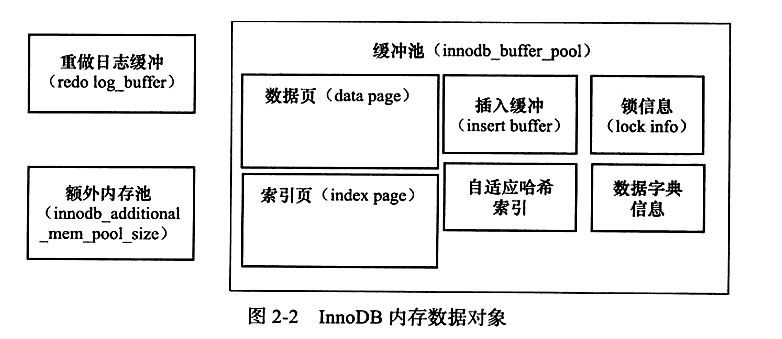
- 索引页
- 数据页
- 插入缓冲
- undo 页
- 自适应哈希索引
- 锁信息
- 数据字典信息
2. 缓存算法
1. LRU(最近最少使用淘汰)
将经常使用的页放在 LRU 列表的最前端,最少使用页放在列表尾端。将新读取的页放到 midpoint 位置(距离尾端的 3/8 出)。可以通过innodb_old_blocks_pct控制插入位置。
midpoint 之前的 new 列表,之后的为 old 列表。new 列表中数据为活跃的数据。
为什么不直接把读取的新页放在列表首部?
部分 sql 操作(索引、数据扫描操作)导致缓冲池中页被刷出,影响缓冲池效率。需要读入大量的数据页,导致许多活跃数据页从列表中移除。
innodb 可以通过设置innodb_old_blocks_time来决定新加入的页从 mid 到列表头部需要等待多久。
3. redo 日志缓冲( redo log buffer)
用于暂时存放 redo log 信息,然后 Innodb 以一定频率刷新到 redo log 文件中。
可以通过 innnodb_log_buffer_size设置缓冲大小。
三种日志刷新到 redo log 文件情况
- Master Thread 每秒刷新
- 事务提交时刷新
- 日志缓冲空间小于一半
2. Checkpoint 技术
解决问题
- 缩短数据恢复时间
- 缓冲池不够时,将脏页刷新到磁盘
- redo log 日志缓冲不够时,刷新脏页
1. Check Point 分类:
- Sharp Checkpoint
- Fuzzy Checkpoing
2. Sharp Checkpoint
默认将数据库关闭时将所有脏页刷新到磁盘中,
参数是 innodb_fast_shutdown=1.
3. Fuzzy Checkpoint
1. Master Thread checkpoint
每 1 或 10 秒将缓冲池中的部分脏页异步刷新到磁盘
2. Async/Sync Flush checkpoint
在重做日志不可用情况下强制刷新一部分页会磁盘。
3. InnoDB 关键特性
1. 插入缓冲
1. Insert Buffer
原理: 当对非聚集索引进行插入或更新操作时,若索引页在缓冲池中,则直接更新索引页。反之,先放到 Insert Buffer 中,然后以一定频率将 Insert Buffer 中的数据和辅助索引页进行merge 操作。
前提:不是唯一索引的辅助索引
问题:为什么不能是唯一索引?
因为唯一索引在更新时,需要将索引页加载进缓冲池中,判断索引是否唯一。将索引页加入了缓冲池中,就失去了使用 Insert Buffer 的意义。
作用:提高插入性能,因为每次插入时不需要立即将数据 merge 到索引页中。
本质:将非聚集索引的写操作缓冲起来,然后将写操作批量 merge 到索引页中。
缺点:写密集情况下会暂用大量缓冲池内存
可以通过 IBUF_POOL_SIZE_PER_MAX_SIZE 设置 Insert buffer 占缓冲池的比例
2. change buffer
insert buffer 的升级版,支持 insert 、delete、 update 语句缓冲。通过 Insert Buffer、 Delete Buffer 、Purge Buffer 来实现缓冲。
Update 语句的实现过程
- 数据的记录标记为删除
- 数据真正删除
将数据记录标记位删除通过,通过 Delete Buffer 来实现。然后通过 Purge Buffer 将数据真正删除。
3. Insert Buffer 内部实现
Insert Buffer 的数据结构是一颗 B+树。
非叶节点存放的查询的 search key .

- space 表示数据插入的表的表空间 id(用于确定插入数据是哪张表)
- marker 兼容老版本的 Insert Buffer
- offset 数据页在表中的偏移量(位置)(用于确定是辅助索引的哪一页)


metadata 中记录信息插入的顺序以及插入信息的类型
Insert Buffer 通过 space 和 offset 确定更新数据的表和辅助索引具体页。
4. Merge Insert Buffer
- 辅助索引页读取到缓冲池中
- Insert Buffer Bitmap 页发现辅助索引页无可用空间时。
- Master Thread 定时进行 Merge
4. 命令
1. innodb_change_buffering
作用: 选择开启哪些缓冲,参数为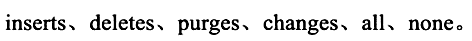
2. innodb_change_buffer_max_size
作用:控制 change buffer 最大内存使用量
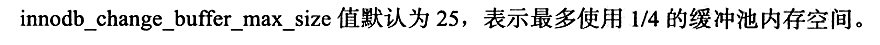
最大值为 50.
2. 两次写
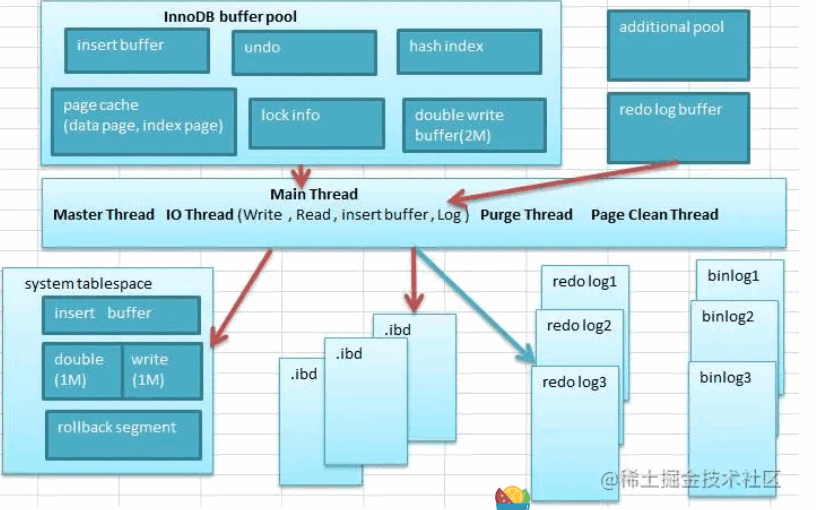
1. 流程
- InnoDB 将脏页写到内存中的 Double write buffer 中
- 然后 DWB 将数据现在写入磁盘上 DWB
- 内存中的 DWB 再将数据刷到磁盘中
2. 作用
通过将脏页数据进行缓存,可以保证数据库异常关闭的情况下,脏页数据未完全写入磁盘时,无法通过 redo log 进行数据的恢复。可以通过 DWB 中之前保存的脏页数据,将数据页写入到磁盘中,然后 redo log 根据脏页进行数据的恢复。
3. 自适应哈希索引(AHI)
1. 概念
由于哈希是一种时间复杂度为 O(1)的查找方法。可以通过在 B+树种建立哈希索引提高查询速度。
自适应哈希索引:存储引擎通过监控索引页的查询条件和频率,来选择是否建立哈希索引。
原理:通过缓冲池中的页
2. 前提
- 连续使用的查询条件一样
- 查询条件使用了 100 次
- 数据页通过该查询条件访问了(页中记录/16)次。
3. 优缺点
- 提高了读取和写入速度
- 只能用来等值查询,不能范围查询
4. 异步 IO
1. 作用
- 异步执行 IO 操作
- IO 合并
2. 异步 IO 操作
同步 IO: 用户发出 IO 请求后,需要等待 IO 请求完成,才能继续发送下一个 IO 请求。
异步 IO: 用户发出 IO 请求后不需要等待 IO 操作完成,可以继续发出 IO 请求。直到所有的 IO 请求发送完后,等待 IO 操作完成。
3. IO 合并
AIO:将多个 IO 请求合并为一个 IO 请求。
例如: 用户需要访问多个连续页时(8,6)、(8,7)、(8,8)可以将多个 IO 操作合并成一个 IO 操作。
(page,offset)指代某个表的某一页。
5. 刷新临接页
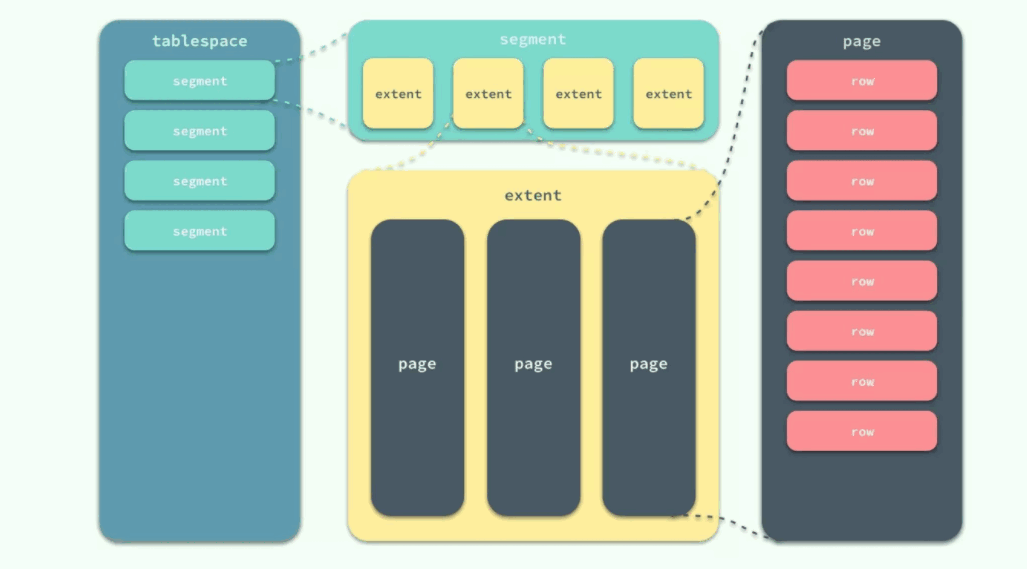
工作原理:刷新脏页时,会检测所在区的所有分页,然后通过 AIO 一起进行刷新。
建议机械硬盘开启特性,固态硬盘由于有着高性能的 IO 读写可以关闭。





